AI Data Quality Best Practices: How to Train Smarter Models
If your AI model is underperforming, the problem probably isn’t the algorithm, but the data.
A 2021 Gartner study revealed that poor data quality costs organizations an average of $12.9 million annually — a truly staggering figure. Think of it this way: your system is always learning from the input you provide, regardless of how intelligent or sophisticated the model is.
For this reason, data quality is not only significant but crucial. Better data lowers bias and increases model accuracy, creating the foundation for smarter, safer, and more dependable AI.
In this article, we discuss the best practices for ensuring high-quality datasets.
Key Takeaways
- Understanding the importance of data quality in artificial intelligence.
- Explore the 7 common Data Quality Mistakes in AI projects.
- Identifying the appropriate Data Quality Metrics to use.
- Knowing how to secure high-quality data improves your AI.
- Discover how Data Quality Tools can improve your Model’s Performance.
- Explore real-world examples of data quality in action.
Why Is Data Quality in AI So Important?
When it comes to artificial intelligence, your model is only as good as the data it learns from. Even the most advanced algorithms will fail if they’re fed incomplete, biased, or irrelevant information. That’s where data quality in AI becomes critical.
Ever heard of GIGO: Garbage in, garbage out — this is a phrase that applies perfectly here, as low-quality data can result in flawed models, misinformed predictions, and serious real-life consequences, especially in sectors like finance, healthcare, or criminal justice.
Ensuring high-quality data powers your AI for a strategic, ongoing approach. It’s not just about one clean dataset. It’s about building an entire system around validation, consistency, and performance tracking. AI isn’t magic — it’s math, and math needs reliable input to work its magic.
7 Common Data Quality Mistakes in AI Projects
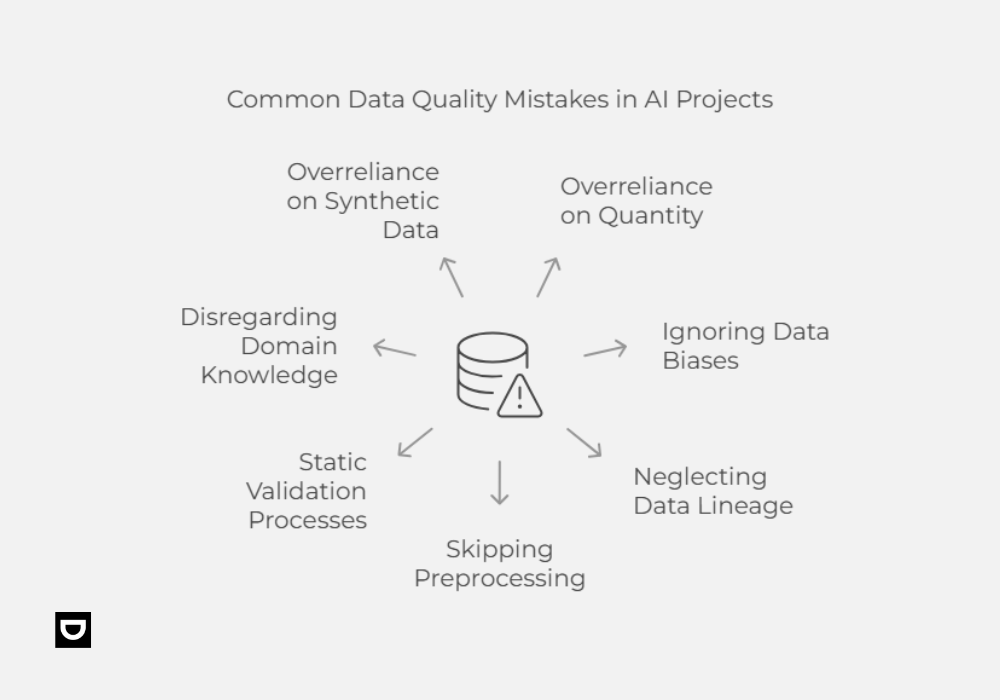
Even with the finest tools and intentions, mistakes in data quality can enter AI pipelines and subtly impair model performance. Here are seven typical errors that cause AI projects to fail, along with tips on how to prevent them:
1. Believing that more information produces better outcomes:
Quality is not necessarily correlated with quantity, as big datasets with irrelevant records or noise might overwhelm your model and mask important trends.
2. Ignoring biases in data:
Biased models are produced when discrimination is embedded in the training data. Your AI will replicate that skew if your data underrepresents particular communities or behaviors, frequently with severe ethical consequences.
3. Ignoring the lineage of data:
You run the risk of misunderstandings and reproducibility issues if you don’t have a clear record of where your data originates from and how it’s altered. Trust and traceability are guaranteed via data lineage.
4. Ignoring preprocessing methods:
During model training, missing variables, duplication, and inconsistent formats can cause serious problems. Poor results are certain if proper cleaning and normalization are skipped.
5. Processes for static validation:
One-time inspections are insufficient. If your data validation isn’t continuous, you’ll overlook problems like schema drift, which gradually impairs model performance.
6. Disregarding domain knowledge:
AI is a contextual problem rather than only a technological one, as irrelevant characteristics and incorrect labeling may result from the data curation process if subject matter experts are not included.
7. Overreliance on synthetic or augmented data:
Even though synthetic data might be useful, depending too much on it can result in models that are not very good at generalizing to real-world situations. This error has led to several well-known AI disasters.
As important as having a smart algorithm is avoiding these mistakes. If you’re ever unsure, revisit your data pipeline and ask yourself: “Is this data suitable for making decisions?”
What Data Quality Metrics Should You Use?
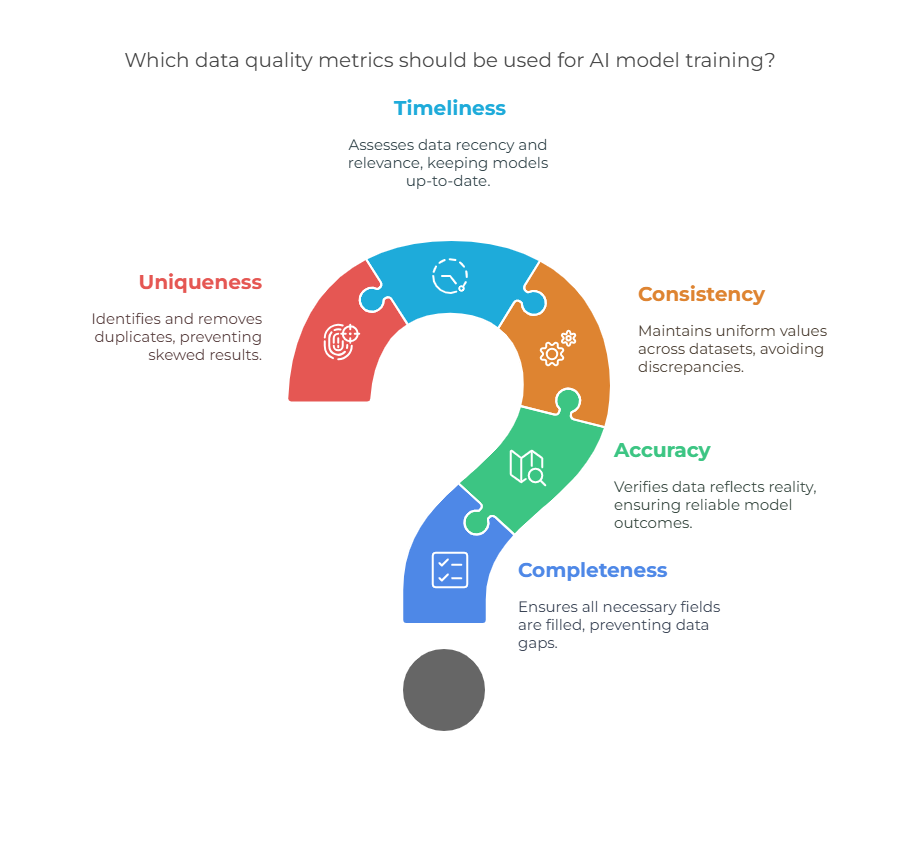
To keep your AI training pipeline sharp, it’s essential to have measurable standards. That’s where data quality metrics come in. These are quantifiable benchmarks you can use to assess whether your data is fit for training your models.
Some of the most effective metrics include:
- Completeness – Are all necessary fields filled?
- Accuracy – Does the data reflect reality?
- Consistency – Are values uniform across datasets?
- Timeliness – How recent and relevant is the data?
- Uniqueness – Are there duplicates that could skew the results?
Tracking these metrics over time creates a data quality assurance loop. As part of your workflow, these metrics can help you spot issues before they turn into model failures.
How Can You Ensure High-Quality Data Powers Your AI?
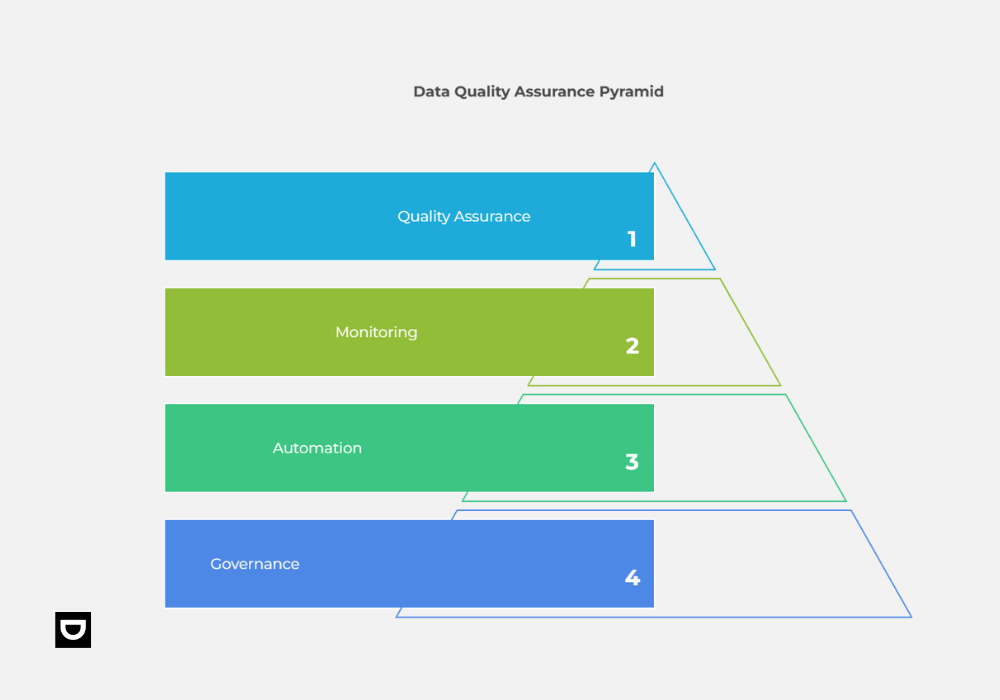
To ensure high-quality data powers your AI, you need to start by establishing clear data governance policies that define the ownership, standards, and access controls.
This governance framework helps create accountability and aligns data practices with either your individual or organizational goals. So, whether you’re feeding data into proprietary solutions, you need a governance policy to help you maintain consistency and prevent quality drift over time.
Right from the onset of your data collection, you need to:
Focus on prioritizing reliable and representative sources.
Ensure you thoroughly document data lineage (that is, the complete journey of the data).
Proactively clean and preprocess all of your datasets.
Handling missing values, de-duplicating records, and correcting anomalies, before your model training.
Integration
Ensure you integrate automated error-handling mechanisms in your ETL (Extract, Transform, Load) processes to catch schema violations and format mismatches early.
Continuous monitoring is equally vital.
Implementation
Implement real-time validation and anomaly detection to detect data drift, which allows for timely retraining and adjustment.
By combining governance, automation, and monitoring, you can be sure to build a sustainable cycle of data quality assurance that powers your AI initiatives effectively.
A Real-life example in this regard is Airbnb’s Data University initiative launched in Q3 2016, which provided tailored training and tools to over 500 employees, boosting weekly active users of their data platform from 30% to 45% within six months and embedding a culture of data literacy and quality across the organization.
How Can Data Quality Tools Improve Your Model’s Performance?
Data quality tools are your frontline defense. They automate the processes of profiling, cleaning, labeling, deduplication, and enrichment — all key components of healthy AI development.
Tools like Great Expectations, Tecton, and Soda Data allow you to set validation rules, test assumptions, and catch anomalies. By embedding these tools into your pipeline, your models benefit from cleaner inputs, which means better generalization and fewer retraining cycles.
A good tool should also integrate seamlessly with cloud infrastructure, MLOps tools, and your version control systems. By combining tools with data quality assurance best practices, you can avoid catastrophic model drift, training bias, and prediction errors.
Real-World Examples of Data Quality in Action
Example 1: DeepMind’s AlphaFold and Protein Predictions
In 2023, Google DeepMind made waves in biology with its AlphaFold project, which predicted 200 million protein structures. What powered that breakthrough? Not just cutting-edge neural networks — it was meticulously curated, high-quality data.
By working with validated experimental datasets and applying strict data quality metrics, they were able to train models with unprecedented precision.
Example 2: IBM Watson’s Oncology Misfire
On the flip side, IBM Watson’s much-hyped oncology AI failed to deliver in real-world hospitals. Investigations revealed the tool was trained on synthetic and limited data, leading to inaccurate cancer treatment suggestions. This failure underscored the importance of data quality assurance in critical fields like healthcare.
Both examples prove that whether you’re making scientific breakthroughs or saving lives, data quality in AI is the silent hero behind your success or the root of your failure.
Conclusion
Investing in data quality tools, metrics, and assurance systems isn’t just good practice, it’s essential for responsible AI development.
The first step in preventing biased predictions and guaranteeing dependable results is what you feed into the model, alongside metrics like accuracy, consistency, and completeness have been shown to make or break the performance of your algorithm. AlphaFold and IBM Watson are two real-world instances that demonstrate how serious the consequences may be.
The model gets smarter with better data. One clean dataset at a time, let’s begin developing AI that we can trust.
Start training smarter.
FAQs
What Is Data Quality in AI?
It refers to the completeness, accuracy, consistency, and reliability of data used to train machine learning models. High-quality data leads to better model performance.
What Tools Help Improve AI Data Quality?
Popular tools include Great Expectations, Soda Data, Tecton, and tools provided by Dumpling AI enable scalable data assurance workflows.
How Often Should Data Be Validated?
Data should be validated continuously — during ingestion, before training, and after deployment — to maintain consistent model performance.
Can Poor Data Ruin Your AI Model?
Absolutely. Inaccurate or biased data can mislead training, resulting in faulty predictions and poor real-world performance.





